
背景
TextMeshProのEditor拡張「Font Asset Creator」を使うと、ttf(TrueType Font)や otf(OpenType Font)のデータを画像化してTMP_Font Assetに変換してくれます。
このとき、Character Set 欄で「ASCII」「Custom Range」「Custom Characters」「Characters From File」などを選択することで生成する文字を絞ることができます。
UIなどで使うフォントが決まっているならば使う文字だけを指定して作成するでしょう。
ですが、ユーザーが入力することがあるなど、できるだけ多くの文字種をカバーしておきたい状況ならばフォントファイルに含まれている文字種すべてをTMP_Font Assetにしてしまいたいときがあるかもしれません。
そのような状況に対しての対応策を考えました。
環境
Unity Editor 2020.2.7f1
TextMeshPro 3.0.4
Kyub EmojiSearch API 1.0.9
方法
以前にも書いた「Kyub EmojiSearch API」に含まれているEditor拡張を使います。
upmからインストールできるのでこちらの記事を参考に導入してください。
インストールできたら、こちらのEditor拡張が追加されているので、Chars in Fontを選択します。
使い方は、Source Font Fileに対象となるttfもしくはotfファイルをセットするだけです。
Character Sequence (Decimal)に大量の数字が出てきたと思います。
ここに何文字含まれているのか手っ取り早知るために、Font Asset Creator を走らせてみます。Character Set を Custom Range にしてこの数字群を Character Sequence (Decimal)に入れます。本当に生成しようとするととても時間がかかるので、Atlas Resolutionをとても小さくして走らせてみると、このような結果が得られました。
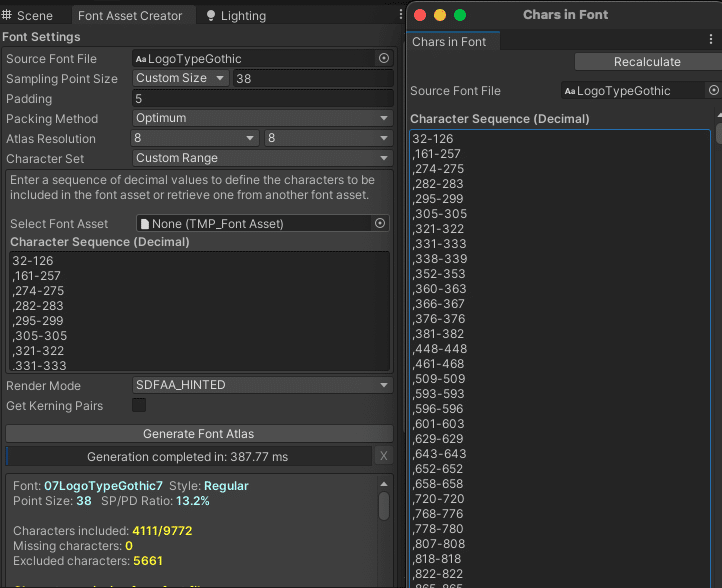
Characters included のところに 4111/9772 という数字が出ています。全部で9,772種類の文字が含まれているようですね。
Atlas Resolution が 4096*4096 より大きくなると一部のAndroid端末で文字化けしてしまうようなので基本的にはそのサイズに収まるように作成しようと思います。
4,096を文字数の平方根で割って、
$4096/\sqrt{9772}=41.4$
となったので、文字サイズを41にしてみましょう。
(……と思ったのですが、普通に50ぐらいでもできました。単位が違うのかな。謎。というかPaddingは考慮しなくて良いのだろうか……。)
注意
フォントによっては文字数が多すぎて詰め詰めスプライトになってしまうので、そこは注意が必要です。
ありとあらゆる文字を含んでくれているフォントファイルならばこういうので絞るのが良さそうです。
kyubuns_Adobe-Japan1-List_ Adobe-Japan1の文字一覧です。
参考(今回は使わなかった方法)
これだけのためにEmoji使わないのにpackage追加するのはなあと思った方はこの辺のもの使っても良いのかもしれないです。
少し設定が必要そうですが。
linux – Finding out what characters a given font supports – Stack Overflow
i’m sorry it’s just a normal problem while using this lib · Issue #1217 · fonttools_fonttools