
ここ10年ぐらいポスターでもゲームでも作るときに常に日本語の良い感じのフォントを探している気がします。
日本語は非常に文字数が多く、もし自分で作るにしても何年かかるのって感じだし(本気で頑張れば1ヶ月ぐらいでできるのかもしれない)、購入しようと思ってもそのコストに見合うお値段って結構高いんですよね。
周囲の人間からもフォント作りたいという声はちらほら聞くのですが現実的ではないなあと。
というわけで今回は手書きフォント作成にあたって字数の多さというめちゃ高ハードルを乗り越えるための対策を考えてみました。
別に新しいことはなくて、検索してみたら同じような考えを持っている人とか実装までやってみている人とかたくさんいました。
部品合成
まずパッと思いつくのは、ひらがなとカタカナ、それから漢字の一部を書いて部品として保存。それを組み合わせて漢字を合成しようという案です。
例えば「黒」ならば「里」と「れっか」で合成できますし、「里」も「田」と「土」からできているので、だいぶ節約できそう!
問題点
- とはいえ書く量はまだだいぶ多そう
- 3つ以上の部品を重ねてできる「黒」「例」なんかは重ねていく方向にどんどん細くなっていって合成しました感が出る
- 「土」で使いまわすとは言え、「地」と「里」では形が違う。同じように使うのか?
- 「田」と「土」を合成するときに真ん中の線が揃っていないと格好悪い
機械学習を使って一部の文字からすべてを合成する
猫も杓子も機械学習ですが、どちらかというと単純な画像合成だしやっぱりこの分野で使えば強そうです。
精度高くてわくわくしますね。
StackGANについてはこちらのブログが日本語で書いてあって詳しかったです。
https://tsunotsuno.hatenablog.com/entry/2018/05/03/114405
「zi2zi」を試してみる
「zi2zi」というツールがkaonashi-tycさんによってGitHubで公開されています。
https://kaonashi-tyc.github.io/2017/04/06/zi2zi.html
https://github.com/kaonashi-tyc/zi2zi
使い方は「README.md」を見ます。
まず準備として、
- Python 2.7
- CUDA
- cudnn
- Tensorflow >= 1.0.1
- Pillow(PIL)
- numpy >= 1.12.1
- scipy >= 0.18.1
- imageio
をインストールします。
Tensorflowは機械学習ライブラリ、CUDAとcudnnはTensorflowを使うために必要なライブラリです。
もちろん自分で学習させることも可能ですが、学習済みモデルについての記述があるのでまずはこれを使ってみます。
こちらからダウンロードした学習済みモデルが入ったフォルダに「PretrainedModel」という名前を付けて「zi2zi」フォルダの中に格納します。
まずは学習用データを作成します。
「zi2zi」フォルダの中に「myfont_dir」フォルダを作成して、改変可能なフリーフォントデータと自作のフォントデータをそれぞれ「myfont.otf」「source_font.otf」などという名前で保存します。
私は「Noto Sans CJK JP(源ノ角ゴシック)」を使わせていただきました。
http://site.oukasei.com/?p=263
このときの拡張子は「otf」かもしれませんし「ttf」や「ttc」かもしれません。
学習済みモデルを使用する場合は、元になるフォントを一種類用意するだけで大丈夫です。
cd zi2zi「zi2zi」フォルダに移動します。
python font2img.py --src_font=myfont_dir/myfont.otf --dst_font=source_font.otf --charset=JP --sample_count=1000 --sample_dir=myfont_dir --label=0 --filter=1 --shuffle=1学習済みモデルを使う場合はは「–dst_font」オプションはあまり関係してこないので、何を指定しても大丈夫です。
例えば、「–dst_font=myfont_dir/myfont.otf」にしても最後に得られるのは同じ画像です。
また、ここで画像に変換するということは自作のフォントデータは画像形式で用意しても良さそうです。
例えば、こんな感じで「白」「黒」「羊」を用意してみました。

python package.py --dir=myfont_dir --save_dir=myfont_dir/save --split_ratio=0.1train.objとval.objに分けます。
「–split_ratio」オプションで分割割合を決めます。
「–split_ratio=0.1」ならtrain:val=9:1になります。
分けられるほどデータ数がないときはこのオプションは使いません。
「save」フォルダは事前に作っておく必要があります。
python infer.py --model_dir=PretrainedModel/ --batch_size=16 --source_obj=myfont_dir/save/train.obj --embedding_ids=1 --save_dir=myfont_dir/result「–model_dir」オプションに「checkpoint」が含まれているフォルダのパスを指定します。
今回のように3つの画像で試すという場合は「–batch_size」オプションを3以下にしないとエラーが出ます。
ValueError: Cannot feed value of shape (6, 256, 256, 6) for Tensor u'real_A_and_B_images:0', which has shape '(16, 256, 256, 6)'
機械学習に限らずデータ扱っていると死ぬほど見るやつですね。もちろん画像のサイズが違っていてもこのエラーメッセージが出ます。
https://github.com/kaonashi-tyc/zi2zi/issues/3
「–embedding_ids」オプションでは文字の太さをかえることができます。
そしてできたのがこの画像です。

GitHubやブログに掲載されていたような字体になりました。
ちなみに、自分で学習回すのもやったのですが、半日計算回してこんな感じのぼやぼや。
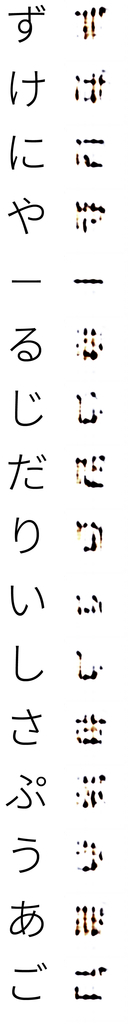
環境整えてまたリベンジしたいと思います。
コードの内容もきちんと理解したい……。
最後に
最終的には手書きフォント作成するためのアプリ開発を目標に、とりあえずは自分で手書きフォントを作ることを目指して引き続き色々と試してみたいと思います。
無料でも可愛いフォントがたくさん公開されていてすごいなと思います。
8:51:22 pmさんのテガキカクットとか、かっちりした文章では使えないかもしれないけれど最高に可愛い。
かなだけだけどプラネタリウムも大好き。
2020/07/07 -
[…] 手書きフォントを作る(ためのツールを作る)①「zi2zi」を使ってみる […]